

If you’ve ever tried researching how to train an LLM on your own data, you’ve probably run into dense research papers, half-working tutorials, and explanations aimed at people with server rooms. It’s a familiar rabbit hole, and it rarely gives you the practical steps you actually need.
This guide fixes that. It explains what training an LLM actually involves, how people do it in the real world, and which parts matter enough to care about, without pretending you’ve got NASA-level hardware sitting under your desk.
If you want a model that understands your documentation, writes code in your style, answers internal questions correctly, or simply stops sounding like a customer-service intern, you’re in the right place.
The quick version
- You can train an LLM on your own data.
- Most teams do it through fine-tuning, not full model training.
- Data quality matters more than hardware.
- Clean, consistent datasets outperform large, messy ones.
- Fine-tuning is much easier with modern tools if your data is well prepared.
That’s the TLDR. The rest of this guide walks through why each step matters and how to approach them in a way that actually produces a reliable model.
How custom data improves LLM performance
Here’s the thing no hype-article tells you: models don’t magically “get” your world. They’re generalists. They’re brilliant generalists, but still generalists. If you want an LLM to behave like someone who’s lived inside your company, your documentation, your coding style, or your niche for years, it needs exposure to your domain.
Imagine hiring a very smart new employee. They understand language, logic, and conversation. But they don’t know:
- why your API returns data the way it does
- what “priority 3 tickets” actually mean
- how your onboarding emails are written
- what counts as a “good” answer in your industry
If you want the model to respond like someone who’s been trained internally – not a confused outsider – then custom training is how you get there. It reduces hallucinations dramatically, increases output consistency, and makes the AI feel like it speaks your language instead of default AI-speak.
The big question: Can you train an LLM on your own data?
Yes. Absolutely. And it’s done every day by researchers, companies, startups, agencies, and solo devs.
But here’s the nuance: you can’t directly train ChatGPT, for example. Not in the way people imagine. You can feed ChatGPT your data via retrieval, but you cannot modify its weights.
What you can train are open-source models like Llama, Mistral, Qwen, Gemma, and Phi. These are exceptionally powerful, and in some cases equal or superior to closed models for domain-specific tasks.
So the better question is: “Should I train the model… or just let it read my data at runtime?”
This brings us to an important difference.
Training vs RAG: What most beginners mix up
A surprising number of people try to train an LLM when all they really needed was RAG (retrieval-augmented generation). But both methods have strengths.
Think of it like learning vs referencing:
- RAG is when the model looks up information as needed, like how we Google things.
- Fine-tuning is when the model truly learns patterns, tone, and structure.
If you want the model to sound like your brand, follow your internal rules, format content like your examples, or write code the way your senior dev does things, you need fine-tuning.
If you simply want the model to answer questions based on a bunch of documents, you want RAG.
Most production systems use both because it gives you accuracy plus consistency.
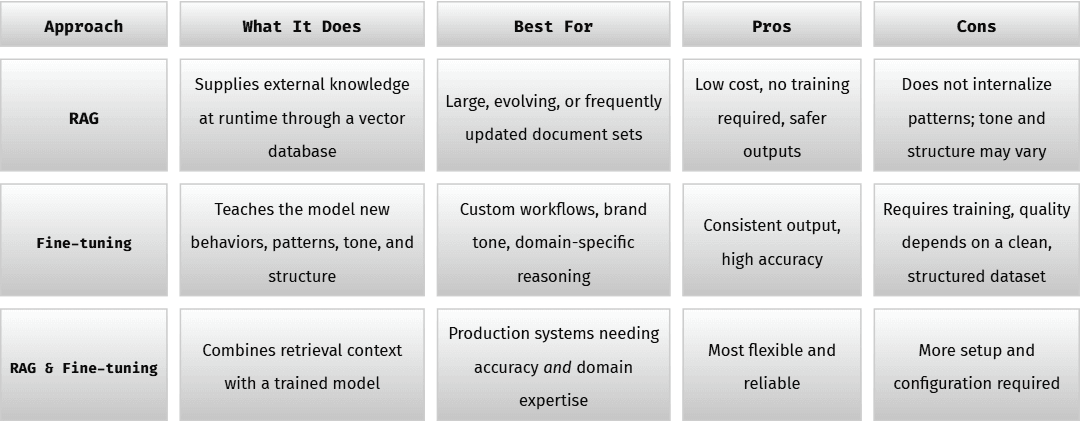
RAG vs Fine-Tuning Quick Comparison Table
How to create training data that doesn’t confuse your model
This is where most people sink the ship. Messy data leads to messy models. It’s that simple.
LLMs don’t want you to be fancy. They want you to be predictable. Think of your model as a straight-A student who panics when the teacher hands out an assignment written in Comic Sans.
Before you touch training tools, ask yourself:
- Does my data read clearly?
- Does each example follow the same structure?
- Would a human understand the task from just the example?
- Am I accidentally mixing tones – formal here, casual there?
If your dataset is inconsistent, the model will average all those styles into a weird smoothie.
A good dataset feels like it was written by one person on one good day.
A real-world example
Let’s say you run a SaaS tool. You want a fine-tuned model that writes support replies the same way your team does.
Your raw data probably includes:
- support threads
- internal notes
- irrelevant greetings
- boilerplate footers
- sarcastic teammate comments that should never see the light of day
If that material makes it into your training dataset, the model can adopt an unprofessional tone that reflects internal conversations rather than the voice you expect it to maintain externally.
Not ideal.
So you’d clean that data, extract clean Q&A pairs, standardize the tone, and turn it into structured examples the model can rely on.
How to ingest data into an LLM (the simple explanation)
Before you start fine-tuning or building any retrieval pipeline, it helps to understand what “ingesting data into an LLM” actually means. The term gets thrown around casually, but in practice it describes two very different processes with very different outcomes. One changes how the model behaves. The other simply gives it more context to work with. Knowing which approach fits your use case will save you time, compute, and quite a bit of frustration.
There are two primary ways an LLM can ingest your data.
1. Ingest for Training
You convert everything into JSONL, with fields like instruction, input, and output. Then you upload it to a fine-tuning tool.
This updates the model’s parameters and creates a modified version tailored to your data.
2. Ingest for Retrieval
You store your documents in a vector database. The model references them as needed.
This doesn’t change the model’s behavior. It just gives it more context to think with.
Most businesses start with retrieval and add fine-tuning once they know what patterns the model needs to learn.
Choosing your base model: What you pick actually matters
Different models have different personalities. A coding model trained on GitHub repos will act differently than a generalist model trained on Common Crawl.
If your project involves anything code-related, it’s worth considering models designed specifically for software tasks. Many of the best open source LLMs for coding consistently outperform general-purpose models when it comes to structured reasoning, debugging, and generating reliable code.
Models in the few-billion parameter range (for example 3B–8B) are suited for lighter compute. Conversely, models in the tens of billions (such as 30B–70B) offer stronger reasoning but require more resources.
A lot of beginners over-estimate model size. A well-trained 7B model can outperform a sloppy 70B one in the right domain.
Fine-tuning step-by-step

Fine-tuning often appears more complex than it really is because many explanations lean heavily on technical language. In reality, the workflow is quite methodical, and once you understand why each step exists, the whole process becomes far easier to navigate.
Here’s the human version.
Step 1: Prepare your dataset
You’re converting your real-world data into neatly structured examples. Most people use formats like:
- instruction → input → output
- question → answer
- dialogue turns
The important part is consistency. If your examples jump between styles, your model will too.
Step 2: Split the dataset
An 80/10/10 split is a common choice and works well in practice. What matters most is isolating the test set. Any leakage between training and testing removes your ability to measure genuine learning versus memorization.
Step 3: Choose a training method
Beginners love QLoRA (Quantized Low-Rank Adaptation) because it dramatically reduces GPU needs. Extra advanced folks sometimes go full fine-tuning, but that’s expensive.
If you have no idea which to pick, QLoRA is almost always the right call. And if you want to dig deeper into how these methods work behind the scenes, there’s a reliable reference on fine-tuning techniques that walks through the technical details clearly.
Step 4: Train the model
Training time is influenced primarily by dataset size and hardware capacity.
In practice, the process may finish within an hour or extend over several hours for more demanding setups. You don’t need to touch most parameters. Start with defaults. Only tweak them when you understand what they do.
Step 5: Evaluate the results
A strong model generalizes from your examples and produces coherent outputs on unseen inputs.
If it starts repeating training data or behaving unpredictably, the root cause is typically a dataset issue rather than a failure in the training process.
Is fine-tuning an LLM hard?
Not anymore. Five years ago, certainly. But the tooling today is substantially more user-friendly. For most teams, the real complexity now comes from evaluating which tool best fits their requirements. The training process itself has become highly automated, with many frameworks offering near one-click fine-tuning once the dataset is prepared.
The tricky part isn’t the training. It’s thinking clearly about what you want your model to learn. That’s why dataset design matters more than anything.
Dataset design shapes everything – the tone it uses, the way it structures answers, the assumptions it makes, and the patterns it prioritizes. If your training examples don’t communicate those expectations consistently, the model has no way to infer them.
How do you train your own dataset?
This question comes up a lot because people often mix up the idea of creating a dataset with training a model. They’re two separate steps.
Creating a dataset is about shaping the examples the model will study, while training is simply the process of feeding those examples into the model.
When you “train your dataset,” what you’re really doing is preparing it so the model can learn from it effectively. You’re teaching through examples, not brute force. A strong dataset shows the model what good output looks like, what tone to use, how to structure information, and which reasoning patterns matter. In many ways, a well-designed dataset works like a set of mini-tutorials written specifically for the model.
The key idea is that your dataset should reflect the standard you want the model to follow. If the examples are inconsistent, unclear, or filled with internal shortcuts that only make sense to your team, the model has no way of interpreting your expectations. But when every example is clear, consistent, and aligned with your goals, the model learns those patterns quickly and reliably.
Costs: What you can expect to spend

You can fine-tune a small model for under US$50 using cloud GPUs. Larger models cost more, but you don’t need them to get excellent results.
Training becomes expensive only when:
- your dataset is enormous
- you’re using full fine-tuning
- you’re experimenting blindly
- you think bigger is always better
Smart prep saves real money. Bad prep burns it like it’s a hobby.
In reality, cost scales with iteration cycles. Cleaner datasets mean fewer training rounds, and fewer rounds mean dramatically lower bills.
Best practices that turn good models into great ones
The performance of a fine-tuned model is largely determined by the quality of the dataset used to teach it.
When examples vary significantly in tone, complexity, or formatting, the model absorbs that variance and produces unpredictable results.
Aligning the dataset around a consistent voice and structure is often the single most effective improvement a team can make.
Good training work avoids:
- inconsistent tone
- mixed-purpose examples
- irrelevant metadata
- contradictory instructions
- noisy inputs
Give the model only the examples that reflect the standard you want it to follow. Anything outside that scope will influence its behavior in ways you may not intend.
FAQs
Yes. Fine-tuning an open-source model on your own dataset is the standard approach for creating AI systems that understand your domain. ChatGPT can work with your data through retrieval, but its core model can’t be retrained.
Not exactly. You can’t fine-tune the ChatGPT models available in the consumer interface, but OpenAI does support fine-tuning for specific versions of its API models.
You can ingest data into an LLM in two main ways.
You can structure it into a training dataset for fine-tuning, which teaches the model new patterns. Or you can store it in a vector database for RAG, allowing the model to reference your documents at runtime. Each approach serves a different purpose and works best for different tasks.
You create LLM training data by turning your examples into structured, consistent formats that models can learn from. Most teams use JSONL files with patterns like instruction-and-response, input-and-output, or Q&A pairs.
The goal is to present clear, repeatable examples the model can generalize from, so consistency in tone, formatting, and structure matters far more than volume.
Not anymore. Modern tooling has made the process far more accessible.
The real challenge is understanding your data and defining the behavior you want the model to learn, not managing the training pipeline itself.
When people ask how to “train” their own dataset, what they’re really asking is how to prepare it so the model can learn from it effectively. The dataset itself isn’t being trained; it’s being organized, structured, and refined so the model can pick up consistent patterns.
That means cleaning the content, standardizing the format, removing noise, and making sure each example clearly demonstrates the behavior you want the model to reproduce. A well-prepared dataset functions like a set of high-quality instructions the model can generalize from.
A Final Note
Custom LLMs succeed when the dataset is well-structured and the training process aligns with the task at hand. When you invest in clean examples and consistent patterns, the model’s performance improves significantly.
The path is straightforward: prepare, train, evaluate, refine.


